SQL-92 is a milestone in setting up the standards of SQL query language for relational database. In SQL-92, an important feature is to define Information_Schema – a series of read-only views for retrieving database metadata.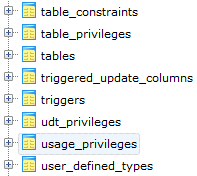
Information_Schema is quite useful when porting one SQL-92 compatible database to another, especially when you have large number of backend scripts which involve metadata operations.
Information_Schema may bring lots of convenience when we build up database-driven solutions since usually these solutions use database metadata quite often.
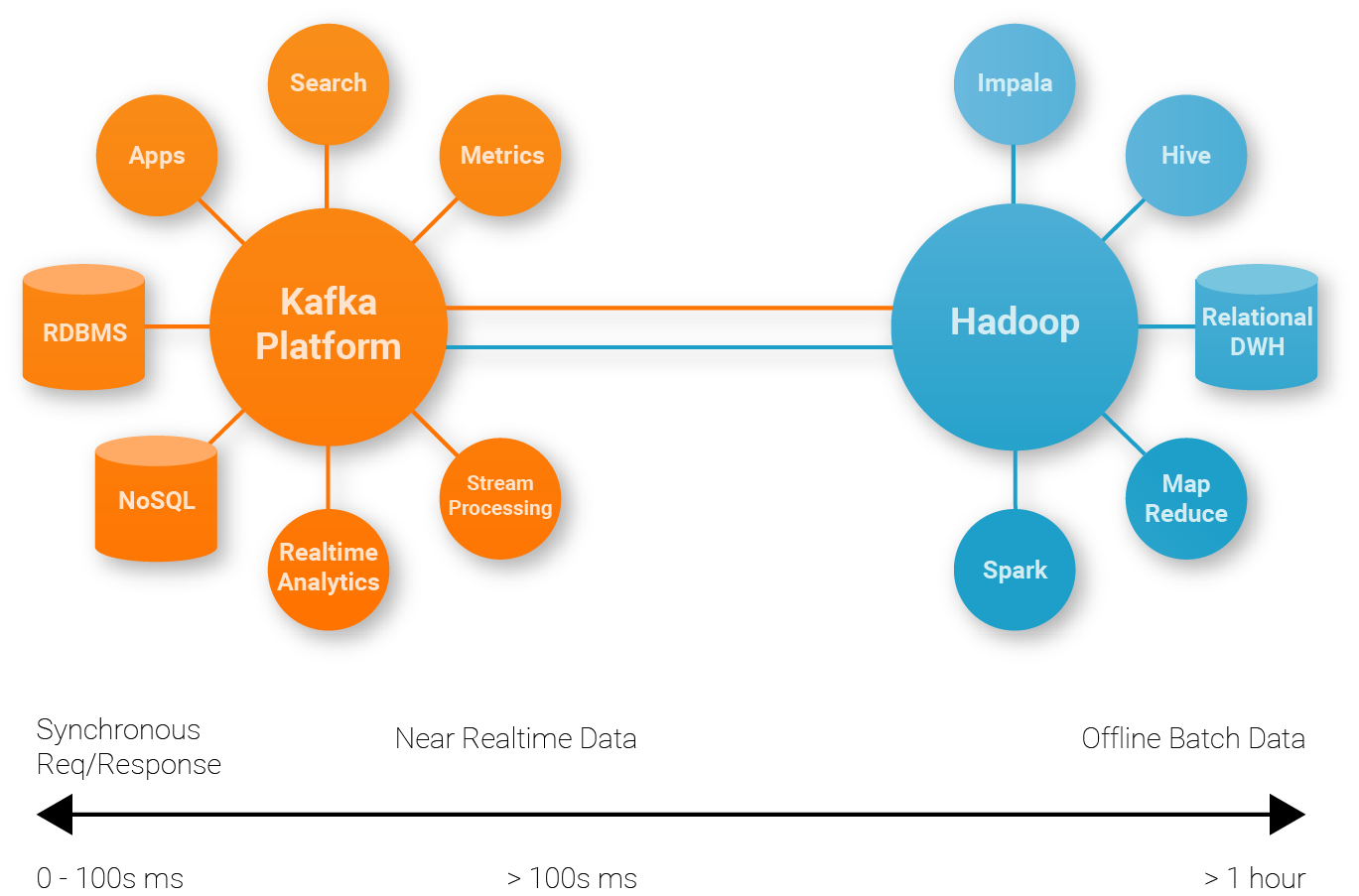
Let’s see which major databases support SQL-92 Information_Schema :
| RDBMS | Rank | SQL-92 Compatible | Information_schema |
|---|---|---|---|
| Oracle | 1st | Oracle data dictionary: desc dict; Open source project: ora-info-schema |
|
| MySQL 5+ | 2nd | MySQL Info Schem... |