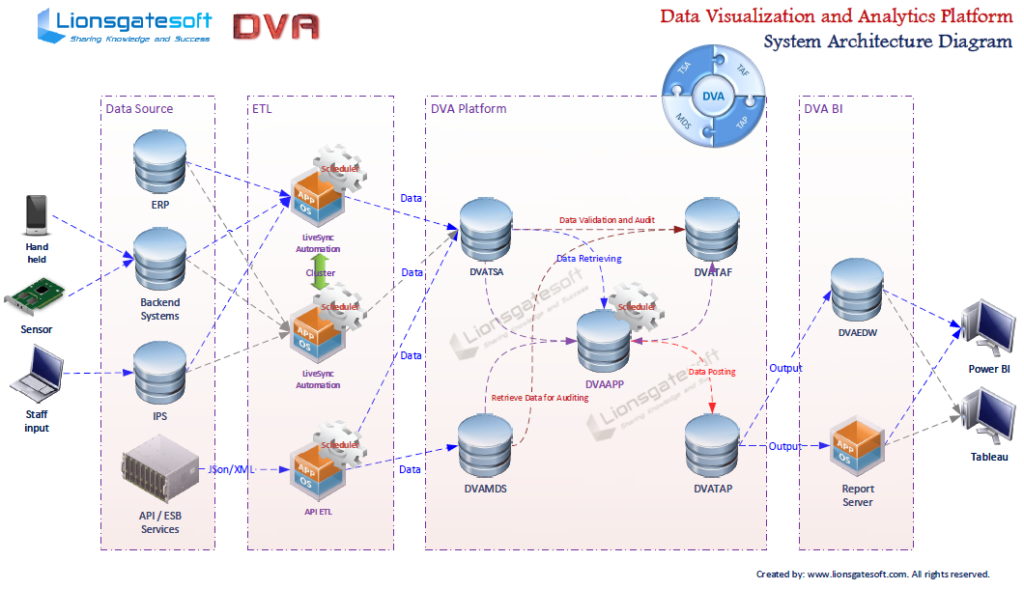
One of my clients is moving its SAP on-premise instances to the cloud. SAP offers Near Zero Downtime Technology (NZDT) to reduce the migration downtime from approx. one week to 6-60 hours (from 6pm Friday to 6am Monday). The purpose of applying NZDT is to secure business continuity. However, it’s not cheap, to pay a million-dollar bill for a weekend! If you know how, then the estimation of building your own in-house developed NZDT component should be less than 50K.
Please be aware, NZDT is neither a new technology, nor the invention of SAP. The discussion of how to implement it is all over the place on the internet. Our Architects have gained enough experience in this area during the past two decades. We have designed and developed sophisticated non-stop 24*7 data replication tool LiveSync ...
Read More